Neurons ‘The Hype’ word which we can hear all over the world
Its nothing but the mimmic of human brain
Neural Network is a network or circuit of neurons, or in a modern sense, an artificial neural network, composed of artificial neurons or nodes Thus a neural network is either a biological neural network, made up of real biological neurons, or an artificial neural network, for solving artificial intelligence (AI) problems.
 ))
))
In Earlier computers Von Neumann architecture is used where it has
- A processing unit that contains an arithmetic logic unit and processor registers
- A control unit that contains an instruction register and program counter
- Memory that stores data and instructions
- External mass storage
- Input and output mechanisms
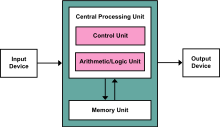 ))
))
In modern computers we describe how we can implement the modern neural netwok in van neuman architecture
Artificial neural networks (ANN) or connectionist systems are computing systems vaguely inspired by the biological neural networks that constitute animal brains.
The neural network itself is not an algorithm, but rather a framework for many different machine learning algorithms to work together and process complex data inputs. Such systems “learn” to perform tasks by considering examples, generally without being programmed with any task-specific rules.
For example, in image recognition, they might learn to identify images that contain cats by analyzing example images that have been manually labeled as “cat” or “no cat” and using the results to identify cats in other images. They do this without any prior knowledge about cats, for example, that they have fur, tails, whiskers and cat-like faces. Instead, they automatically generate identifying characteristics from the learning material that they process
ANN and Perceptron
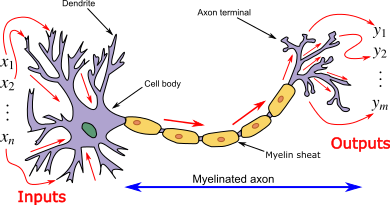
Today, most scientists caution against taking this analogy too seriously, as neural networks are strictly designed for solving machine learning problems, rather than accurately depicting the brain, while a completely separate field called computational neuroscience has taken up the the challenge of faithfully modeling the brain. Nevertheless, the metaphor of the core unit of neural networks as a simplified biological neuron has stuck over the decades. The progression from biological neurons to artificial ones can be summarized by the following figures.
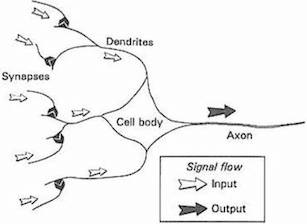 ))
))
 ))
))
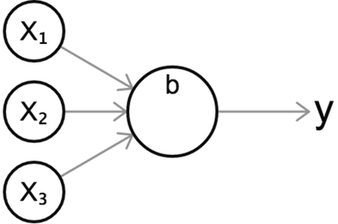
For a Simple Perceptron the neuron will mimics as
From linear classifiers to neurons
First we should know about linear classfifier
The input to a 2d linear classifier or regressor has the form:
\begin{eqnarray} f(x_1, x_2) = b + w_1 x_1 + w_2 x_2 \end{eqnarray}
More generally, in any number of dimensions, it can be expressed as
Regresssion
In the case of regression, gives us our predicted output, given the input vector . In the case of classification, our predicted class is given by
Each weight, , can be interpreted as signifying the relative influence of the input that it’s multiplied by, . The term in the equation is often called the bias, because it controls how predisposed the neuron is to firing a 1 or 0, irrespective of the weights. A high bias makes the neuron require a larger input to output a 1, and a lower one makes it easier.
We can get from this formula to a full-fledged neural network by introducing two innovations. The first is the addition of an activation function, which turns our linear discriminator into what’s called a neuron, or a “unit” (to dissociate them from the brain analogy). The second innovation is an architecture of neurons which are connected sequentially in layers. We will introduce these innovations in that order.
Classification
we introduced binary classification by simply thresholding the output at 0; If our output was positive, we’d classify positively, and if it was negative, we’d classify negatively. For neural networks, it would be reasonable to adapt this approach for the final neuron, and classify positively if the output neuron scores above some threshold. For example, we can threshold at 0.5 for sigmoid neurons which are always positive.
But what if we have multiple classes? One option might be to create intervals in the output neuron which correspond to each class, but this would be problematic for reasons that we will learn about when we look at how neural networks are trained. Instead, neural networks are adapted for classification by having one output neuron for each class. We do a forward pass and our prediction is the class corresponding to the neuron which received the highest value. Let’s have a look at an example.
Example
Let’s now tackle a real world example of classification using neural networks, the task of recognizing and labeling images of handwritten digits. We are going to use the MNIST dataset, which contains 60,000 labeled images of handwritten digits sized 28x28 pixels, whose classification accuracy serves as a common benchmark in machine learning research. Below is a random sample of images found in the dataset.
 ))
))
A random sample of MNIST handwritten digits The way we setup a neural network to classify these images is by having the raw pixel values be our first layer inputs, and having 10 output classes, one for each of our digit classes from 0 to 9. Since they are grayscale images, each pixel has a brightness value between 0 (black) and 255 (white). All the MNIST images are 28x28, so they contain 784 pixels. We can unroll these into a single array of inputs, like in the following figure.
 ))
))
How to input an image into a neural network The important thing to realize is that although this network seems a lot more imposing than our simple 3x2x1 network in the previous chapter, it works exactly as before, just with many more neurons. Each neuron in the first hidden layer receives all the inputs from the first layer. For the output layer, we’ll now have ten neurons rather than just one, with full connections between it and the hidden layer, as before. Each of the ten output neurons is assigned to one class label; the first one is for the digit 0, the second for 1, and so on.
After the neural network has been trained – something we’ll talk about in more detail in a future chapter – we can predict the digit associated with unknown samples by running them through the same network and observing the output values. The predicted digit is that whose output neuron has the highest value at the end. The following demo shows this in action; click “next” to flip through more predictions.